
Makine Öğrenmesi Geliştirirken Dikkat Edilecek 12 Püf Nokta
Makine öğrenmesi konusunda bilmeniz gereken 12 şey
Makine öğrenme algoritmalarının çalışma şekli geleneksel programlamadan farklıdır. Belli rutinleri işlemek yerine, örneklerden genelleme yaparak önemli görevleri nasıl yerine getireceğini hesaplayabilir. Geleneksel programlamanın mümkün olmadığı durumlarda makine öğrenmesi ile geliştirilmiş olan yapay zeka uygulamaları genellikle uygun ve düşük maliyetli olmaktadır.
Daha fazla veriniz varsa, daha iddialı sorunlarla da başedilebilirsiniz. Sonuçta, makine öğrenmesi ile üretilmiş kodları birçok alanda yaygın olarak kullanabilirsiniz. Bununla birlikte, başarılı yapay zeka uygulamaları geliştirmek, ders kitaplarında bulunması zor olan önemli miktarda püf nokta da gerektirmektedir. Bir sonraki makine öğrenme problemlerinizi çözmek için düşünürken buradaki 12 maddenin son derece faydalı olacağına inanıyorum.
1 - "Teori" her zaman "Pratik" ile uyumlu çalışmaz
Makine öğrenmesi hakkındaki makalelerde birçok şey garantiymiş gibi bahsedilir. Mesela iyi genellemeyi sağlamak için gereken tek şeyin örnek sayısını arttırmak olduğu iddia edilir. Ya da sonsuz sayıda veri verilirse doğru sınıflandırıcının kendiliğinden oluşacağıdır.
Bu tür teorik ifadelerin temel anlamı bir garanti vermek değildir. Sadece algoritma tasarlarken pratik kararlar almak için anlayış ve itici güç kaynağıdır.
2 - Belirlediğiniz Özellikler (Feature) Sizin Başarınızın Anahtarıdır
Yapılan makine öğrenmesi çalışmalarının birçoğu başarısız olmaktadır. Yeterli doğrulukla çalışmmaktadırlar. Bunun temel sebebi çok nettir. Özelliklerin seçimini ne kadar doğru yaptığınızla alakalıdır. Özellikleri seçerken genellikle, sezgiler, yaratıcılık teknik yetenekler kadar önemlidir. Bu da makine öğrenmesinin en ilginç kısımlardan biridir.
Her biri sınıfla iyi ilişkilendirilmiş birçok bağımsız özellik varsa, öğrenmek kolaydır.
Bir makine öğrenme projesinde zamanın en az kısmı makine öğrenimi için harcanır. Verileri toplamak, entegre etmek, temizlemek ve ön işleme yapmak oldukça çok zaman alır. Sonrasında da deneme yanılma yaparak hangi özellikler kullanılacağı bulunmaya çalışılır
3 - Sade olması Her Zaman Doğru Yol Demek Değildir
Makine öğrenmesinde temel bir anlayış vardır. "İki sınıflandırıcı içinde basit olan muhtemelen en düşük test hatasına sahip olacaktır." şeklinde olan inanç çoğu zaman işe yarayabilir. Ama tam tersine örnekler de oldukça fazladır. Basit ve sade olması kolay anlaşılabilir olmasına ve hızlı entegre edebilmemize yarıyor olabilir. Ama bu basitlik problemin çözümü ile alakalı olmayabilir.
Neden sonuç ilişkilerini açıklamak zordur. Temel problemin ne olduğunu ortaya koymalısınız, olası sonuçlara nasıl etkilerinin olduğunu, aralarındaki korelasyonu açıklamak zorundasınızdır. Bunun için deneyler yapar raporlar tutarsınız. Tamamen zorlayıcı bir süreçtir. Aksi ise çok basittir. "Kader" der geçersiniz. Basit olması doğruluğunun daha fazla doğru olmasını gerektirmez.
4 - Tanımlanabilir olması Öğrenilebilir Olmasını Gerektirmez
Her fonksiyon tanımlanabilir ama bu fonksiyonların hepsinin makine öğrenmesi yöntemlerine uygulanabileceği anlamına gelmez. Her yöntemin kendi özel sınırlamaları vardır. Mesela bir karar ağacı örnek sayısından daha çok yaprağa sahipse bu model uygulanamaz. Sınırlı veri, zaman ve bellek sahibi olduğumuz gözden kaçırılmamalıdır. Standart makine öğrenimi yöntemleri bile mümkün olan tüm işlevlerin yalnızca küçük bir alt kümesini öğrenebilir.
Bu nedenle kilit soru, cevabın genellikle önemsiz olduğu "Tanımlanabilir mi" değil, "Öğrenilebilir mi?" olmalıdır. Farklı makine öğrenmesi yöntemlerini denemeliyiz (ve muhtemelen onları birleştirmek).

5 - Korelasyon Olması Sebep-Sonuç İlişkisini Gerektirmez
Satışlarını incelediğimiz süpermarkette bira ve çocuk bezinin birlikte satıldığını görmemiz bunların arasında bir korelasyon olduğunu gösterebilir. Ama bu iki ürün arasında bir sebep sonuç ilişkisi olduğunu göstermez. Tabii ki buna bir açıklama getirebilirsiniz. Çocuk bezi kullanılıyorsa evde bir bebek vardır. Dışarı çok çıkılmıyordur o yüzden de evde bira tüketiliyor şeklinde. Ama bu gerçek de olmayabilir.
Çünkü bazen de yağmurlu havalarda hamburger ekmeğinin çok satıldığı gibi korelasyonlar yakalanır ki bunu açıklamak çok daha zordur. Belki açıklayabiliriz ama önemli olan bunun bize bazı ipuçlarını vereceği ve satışları arttırmak için önerileri buna göre yapmamızdır.
6 - Makine öğrenmesinin 3 Aşaması. Tasarım + Değerlendirme + İyileştirme
Tüm makine öğrenme algoritmaları genel olarak sadece 3 bileşenin kombinasyonundan oluşur:
- Tasarım: Ne tür bir sınıflandırıcı (cleassifier) kullanacağınıza karar vermelisiniz. Bu sınıflandırıcıda hangi özellikleri (feature) kullanacaksınız. Kullanacağınız veriyi neye göre sınıflandıracak ve hang isonuca varacaksınız. Uygulamanızın başarısı bu tasarıma bağlıdır. Eğer sorununuzla ilişkili bir sınıflandırıcı, özellik listesi kullanmazsanız doğru sonuç beklemek gereksizdir.
- Değerlendirme: İyi sınıflandırıcıları kötü sınıflandırmacılardan ayırmak için bir değerlendirme süreci gerekecektir.
- İyileştirme: Sınıflandırıcıları arasında en yüksek skorlama için arama yapmak için bir yönteme ihtiyacımız olacaktır. İyileştirme tekniğinin seçimi verimliliğin anahtarıdır.
7 - Genelleme Her Zaman İşe Yarar
Makine öğrenmesinin temel amacı, eğitim setindeki örneklerden öğrenerek sonrasında da genelleme yapmak ve karar vermektir. Eğitim setinizde ne kadar çok veri olursa olsun, çalışma zamanında aynı verileri tekrar görme olasılığınız çok düşüktür. Çoğu zaman ise imkansızdır.
Eğitim kümesinde iyi şeyler yapmak kolaydır. Eğitim verilerini kullanarak uygulama başarısını test etmek ve başarılı olduğunu zannetmek en yaygın hatalardan birisidir. Makine öğrenme tekniklerine yeni başlayanlar olarak hepimiz bu hataları ilk başlarda yapmışızdır.
Gene benzer bir yaygın hata da seçilen sınıflandırıcıyı yeni verilere göre test etmektir. Bu durum rastgele tahminlerden daha öteye gidemez. Eğer bir makine öğrenmesi yazacaksanız verilerden bir kısmını test etmek için kendinize saklaöalısınız. Sonra da geliştirdiğiniz sınıflandırıcıyı bu verilerle test edin.
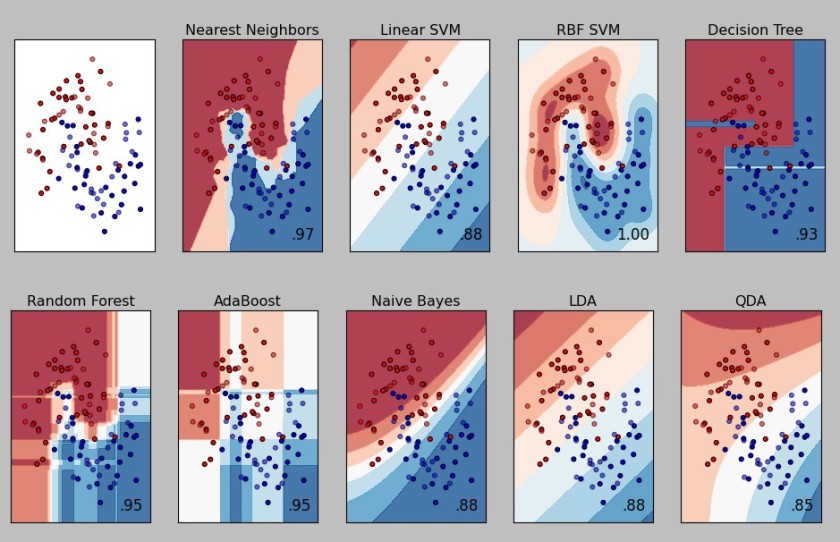
8 - Sadece Veri Kesinlikle Yetmez
Hedefi belli olan bir yapay zekanın en temel gerçeği: Ne kadar çok olursa olsun, tek başına veri asla yeterli olmaz.
Bu oldukça rahatsız edici haberlere benziyor. Öyleyse nasıl bir şey öğrenmeyi umut ediyoruz? Aslında benzer sınıflara sahip benzer örnekler, sınırlı bağımlılıklar veya sınırlı karmaşıklık gibi çok genel varsayımlar genellikle çok iyi sonuç verir. Makine öğrenmesinin başarısının en önemli özelliğidir. Bizim yapmamız gereken verilerin özelliklerini net bir şekilde ayrıştırabilmiş olmaktır. Sorunun çözümüne ilişkin bir öngörümüzün olması gerekmektedir. Aksi takdirde veriden bilgi çıkartamazsınız.
Makine öğrenimi bir çeşit büyü değildir. Hiçbir şey vermeden bir şey yapamaz. Yaptığı, daha azından daha fazlasını elde etmektir. Programlama, tam bir mühendislik işidir: her şeyi sıfırdan inşa etmek zorundasınızdır. Makine öğrenmesinde ise işin bir kısmını bırakırsınız. Aynı bir çiftçiliğe benzer, işin asıl kısmını doğa yapar. Çiftçiler sadece ürün yetiştirmek için tohumları toprakla birleştirirler. Yapay zeka geliştiricileri de bilgiyi veriyle birleştirirler.
9 - Daha Çok Veri, Daha Akıllı Bir Algoritmadan İyidir
Yazılım işinde en kısıtlı kaynaklar hep aynıdır, "zaman" ve "hafıza". Makine öğrenmesiyle üçüncü bir tane daha eklendi. "Veri".
Eskiden veri bulmak çok zordu. Ama şu an o kadar çok veri var ki. Problem artık bu verileri işleme konusuna geri dönmüş durumda. IoT cihazlarından ya da sosyal medyadan ya da sizin kendi uygulama verilerinizden. Nereden geldiğinden bağımsız olarak dağlar kadar çok veri ile karşı karşıyayız. Onları işleyebilecek işlem zamanımız olduğu sürece de o kadar çok veriyi kullanabilmekteyiz.
İşleyebileceğiniz veri miktarını arttırdığınız zaman başarımınız da çok yüksek miktarlara çıkacaktır. Tabii ki düzgün özellikleri seçmiş ve doğru sınıflandırıcı kullandıysanız gibi diğer püf noktalara da dikkat ettiğinizi var sayarak.
10 - Tek Çiçekle Bahar Gelmez
Makine öğrenmesine başladığımız ilk zamanlarda bize en yakın gelen yöntemi öğrenmek ve o yöntemi tüm problemlerde kullanmaya çalışmak hepimizin davranış şekli olmuştur. Çok sevdiğim bir laf vardır. Elinde tek alet çekiç olan kişi bütün problemleri çivi gibi görmeye başlar. Bu şekilde aynı yönteme saplanıp kaldığımız zaman birçok fırsatı kaçırabiliriz.
Tek modelin dışında yöntemlere de hakim olmalıyız. Hatta birçok problemin çözümü birden fazla yöntemi aynı anda koşturup sonrasında da topluluk öğrenmesi (ensemble) ile bir oylama yapmak ve sonuç kararını ona göre almak en doğru yöntem olabilir.
11 - Ezberlemenin Farklı Yüzleri Vardır, Her an Karşınıza Çıkabilir
Öğrencilerin iyi not almak için sınavda kopya çekmesi gibidir aslında yaşanan durum. Öğrenci konuyu öğrenmiş olmaz ama sisteme göre mükemmel bir iş çıkarmış durumdadır. Buna overfitting de denir. Eğer modelimiz, eğitim için kullandığımız veri setimiz üzerinde gereğinden fazla çalışıp ezber yapmaya başlamışsa ya da eğitim setimiz tek düze ise overfitting olma riski büyük demektir.
Modeller de değeri tutturmak için her tür pisliğe başvurabilirler. Bazı durumlarda algoritmanız esas problemi çözmekten uzaklaşır. Sadecekendisine verilen değerleri tutturmaya odaklanır. Buna o kadar odaklanır ki değerleri mükemmel tutturur. Bu yüzden de esas çözmesi gereken problemi çözmekten uzaklaşmış olur. Bunu önlemek için daha çok veri ve çapraz sorgulama gerektirebilir.
Overfitting’den kaçarken düşülebilecek tam tersi bir durum daha vardır. Bu durumda da veri setimizdeki önemli özellikleri yakalayamayıp gerekli öğrenmeyi yapamamamış oluruz. Farketmesi daha kolaydır. Daha fazla veri kullanılarak ya da daha karmaşık bir model kullanılarak çözülebilir.
Bu denge durumunu yakalama çabasına Bias-Variance (Taraflılık - Varyans Dengesi) denilmekte.
Taraflılık
Taraflılık modelin ne kadar yanlış olduğunu ölçer. Genelleştirme hatasının bu parçası, yanlış varsayımlara dayanır. Modelimiz veri için yeterince karmaşık olmadığından önyargılı bir şekilde yanlış tahminler yapıyordur. Burada model elinden geleni yapıyor aslında ama veri seti için yeterince karmaşık bir yapısı olmadığı için yetersiz kalıyor
Örneğin, veri ikinci dereceden polinom iken verinin lineer olduğunu varsaymak gibi durumlarda bu hataya düşeriz. Taraflılık, modelimizin problemin çözümünü içermediğini gösterir. Modelimizin zayıf kaldığı bu duruma eksik öğrenme (underfitting) denir.
Varyans
Varyans, modelin tahmin ettiği verilerin, gerçek verilerin etrafında nasıl (ne kadar) saçıldığını ölçer.Eğer model veriye çok fazla uyuyorsa bu ezberlreme durumunu oluşturur. Genelleştirme hatasının bu parçasına, modelin eğitim verisindeki düşük değişimlere aşırı duyarlılığı sebep olur.
Yüksek bias durumunda modelimiz çok basit oluyor, variance yüksek olduğunda (bias’ın düşük olması demek) modelimiz çok kompleks bir hal almış oluyor. Bu durumda yapılabilecek en iyi şey arada bir optimum durum yakalayıp, modelimizi bu şekilde geliştirmemiz gerekiyor.
12 - Yüksek Boyutların Lanetinden Uzak Durun
Aşırı uyumdan sonra, makine öğrenmesindeki en büyük sorun çok boyutlu sorunlardır. Sınıflandırılması amaçlanan veri kümesinde değerlendirmeye katılacak ayırt edici özellik sayısının çok fazla olması durumunda ortaya çıkar. Yapılacak sınıflandırmanın fazlaca isabetsizleşmesi, hatta sınıflandırılma yapılamaması durumu oluşur.
Yüksek boyutluluk (the curse of dimensionality) ifadesi, 1961'de Bellman tarafından ortaya atılmıştır. Makine öğrenmesinde çok daha fazla şey ifade eden bu kavram, veri yüksek boyutlu olduğunda, düşük boyutlarda iyi çalışan pek çok algoritmanın zorlanacağına değinmek için ortaya atılmıştır. Makine öğrenmesinde örneklerin boyut sayısı (özellik sayısı) büyüdükçe doğru bir şekilde genelleme yapmak üstsel olarak artarak zorlaşmaktadır.
Yüksek boyutlarla ilgili asıl sorun, üç boyutlu bir dünyadan gelen sezgilerimizle yaşıyor, düşünüyor olmamızdır. Çoğu zaman yüksek boyutlu olan problemleri anlamakta zorlanırız. 2 veya 3 boyutlu bir sınıflandırıcı oluşturmak kolaydır; görsel incelemeyle farklı sınıf örnekleri arasında makul bir yer bulabiliriz. Ancak yüksek boyutlarda, neler olduğunu anlamak çok zordur.
İyi bir sınıflandırıcı tasarlamak yüksek boyutlarla çalışırken zorlaşır. Doğal olarak, daha fazla özellik (feature) ile çalışmak güzel birşey gibi gelebilir ama boyutsallığı arttırdığınız zaman gerçekten başınız ağrımaya başlayacaktır.
Sen Ne Düşünüyorsun ?